
Spiaminto
Supabase 무료플랜 임베딩 데이터 용량 초과 대응후기 본문
텍스트 임베딩을 저장할 vector 지원 DB 호스팅 서비스 중 supabase 를 이용해 보았는데, 이때 용량이 생각보다 부족했고 이를 해결하기 위해 한 여러 고민을 기록 해본다.
Supabase 무료 플랜의 경우 DB 공간을 총 0.5GB 를 제공하는데 스크래핑한 글과 댓글, 임베딩된 벡터를 모두 저장하기에는 많이 부족한 용량이었다. 다른 방법을을 모두 시도해 보았음에도 최종적으로 256차원 벡터값을 포함하는 테이블 16만행이 0.46GB 를 차지했기 때문에 더이상 저장할 공간이 없어 데이터를 모두 AWS RDS 로 옮겼다.
아래는 AWS RDS 로 옮기기 전에 시도했던 방법들이다.
1. 글과 댓글을 다른 DB 로 분리
첫 문제 발생 당시 글은 77만개(대부분 댓글 없음) 임베딩은 4만개 였는데, 이때 이미 DB 용량은 1GB 를 넘어있었다.
이중 댓글이 없는 50만개 정도의 글은 삭제하고, 댓글이 있는 약 16만개의 글과 70만개 정도의 댓글을 CSV 로 export 하여 다른 호스팅 서비스의 MySQL DB 에 임포트 하였다.
export 는 supabase 의 대시보드에서 'export table as .csv' 버튼을 통해 진행했고, mysql 에서 'table data import wizard' 를 통해 import 를 시도햇다. 이때 다음과 같은 문제들이 발생했다.
문제 1 한글 인코딩을 지원하지 않음. (Unhandled Exception cp949 발생)
인터넷에서는 메모장으로 UTF-8 로 변환 저장하면 된다던데 난 안되서 ANSI 로 변환 후 저장했더니 import 가 가능해졌다.
문제 2 타입문제 boolean, timestampz (timestamp with timezone)
boolean 형의 경우 supabase 에서 export 하면 true 의 경우 't' , false 의 경우 'f' 로 export 된다. 나는 mysql 에서 tinyint 형을 사용하여 boolean 을 저장할 예정이었는데 일단 varchar(1) 로 받아 처리했다.
timestampz 형의 경우 supabase 에서 timestamp 에 timezone 이 추가된 형식인 timestampz 로 시간 데이터를 저장하는것을 권장한다고 해서 그렇게 했더니 mysql 의 timestamp 로 import 할때 값이 형식에 안맞다며 문제가 발생했다. 이는 csv 를 메모장으로 연 뒤, '바꾸기' (ctrl + h) 기능을 통해 '+09' 를 ''(문자없음) 로 바꾸어 해결했다.
문제 3 FieldSeperator, Enclose Strings in 설정 (Unhandled Exception list index out of range 발생)
csv 로 export 된 파일을 직접 메모장 등으로 열어 필드구분자와 문자열 구분자를 확인하고 기입하면 해결된다.
supabase 의 웹 대시보드에서 export 한 csv 파일은 ',' 로 필드를 구분하며 문자열의 경우 '|' 로 감싸져 있었다. 따라서 다음과 같이 설정해준다. (아래 화면은 import 창에서 exception 안내창을 닫고 스패너 아이콘을 누르면 볼수 있다)
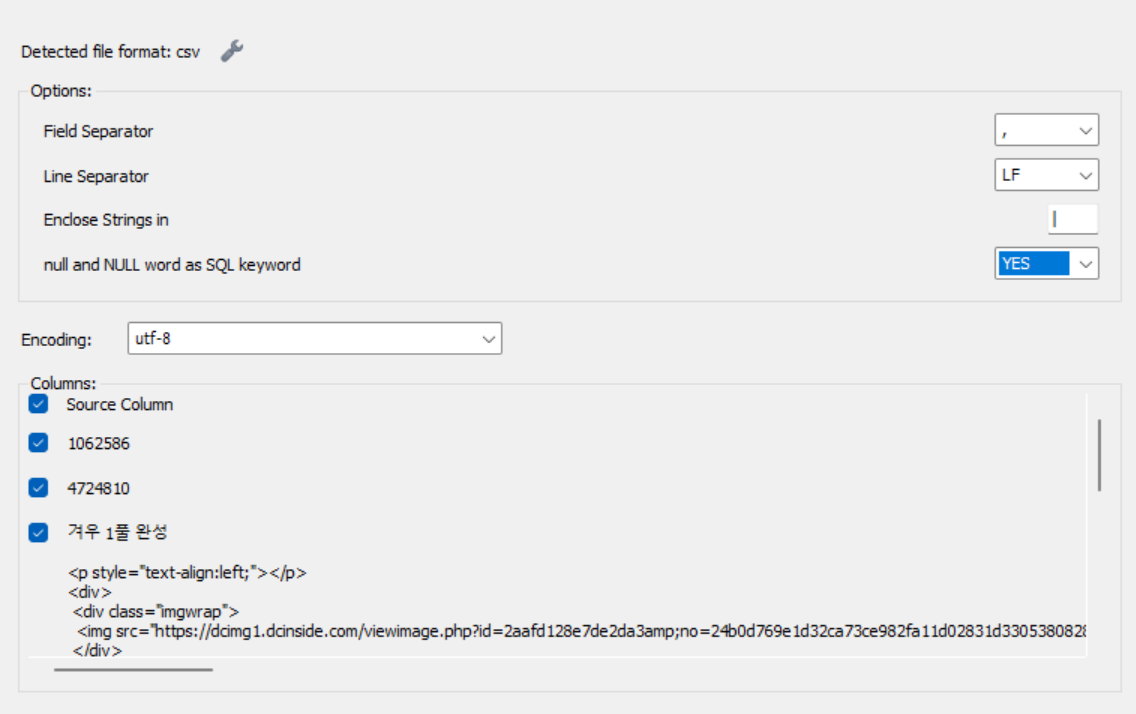
문제 4 속도
위와같이 설정하고 import 할 경우, 로컬 데이터베이스를 기준으로 10분 이상 기다렸음에도 porgress 진행바가 조금밖에 진행되질 않았다. 글의 경우 15만건 정도, 댓글의 경우 70만건 정도 있었기에 무한정 기다릴 수 없어서 'table data import wizard' 대신 LOAD DATA 문을 사용했다. 이때 csv 파일을 ' mysql 설치 경로/data/[스키마명]/ ' 아래에 위치시키면 별도의 설정 없이 읽어올 수 있었다.

12초만에 16만건 정도를 읽었다. table data import wizard 보다 월등히 빠른 결과다.
위와같이 글과 댓글 데이터를 분리하여 용량을 확보했지만, 그럼에도 불구하고 한계는 금방 찾아왔다.
2. 벡터 사이즈 축소
2.1 1536차원 벡터 용량
당시 openai 의 임베딩 모델 중 ' text-embedding-3-small ' 을 사용하고 있었다. 해당 모델은 텍스트를 1536차원의 벡터값으로 임베딩 해주는데 이렇게 임베딩 된 벡터값을 1만개 저장한 용량이 다음과 같다.
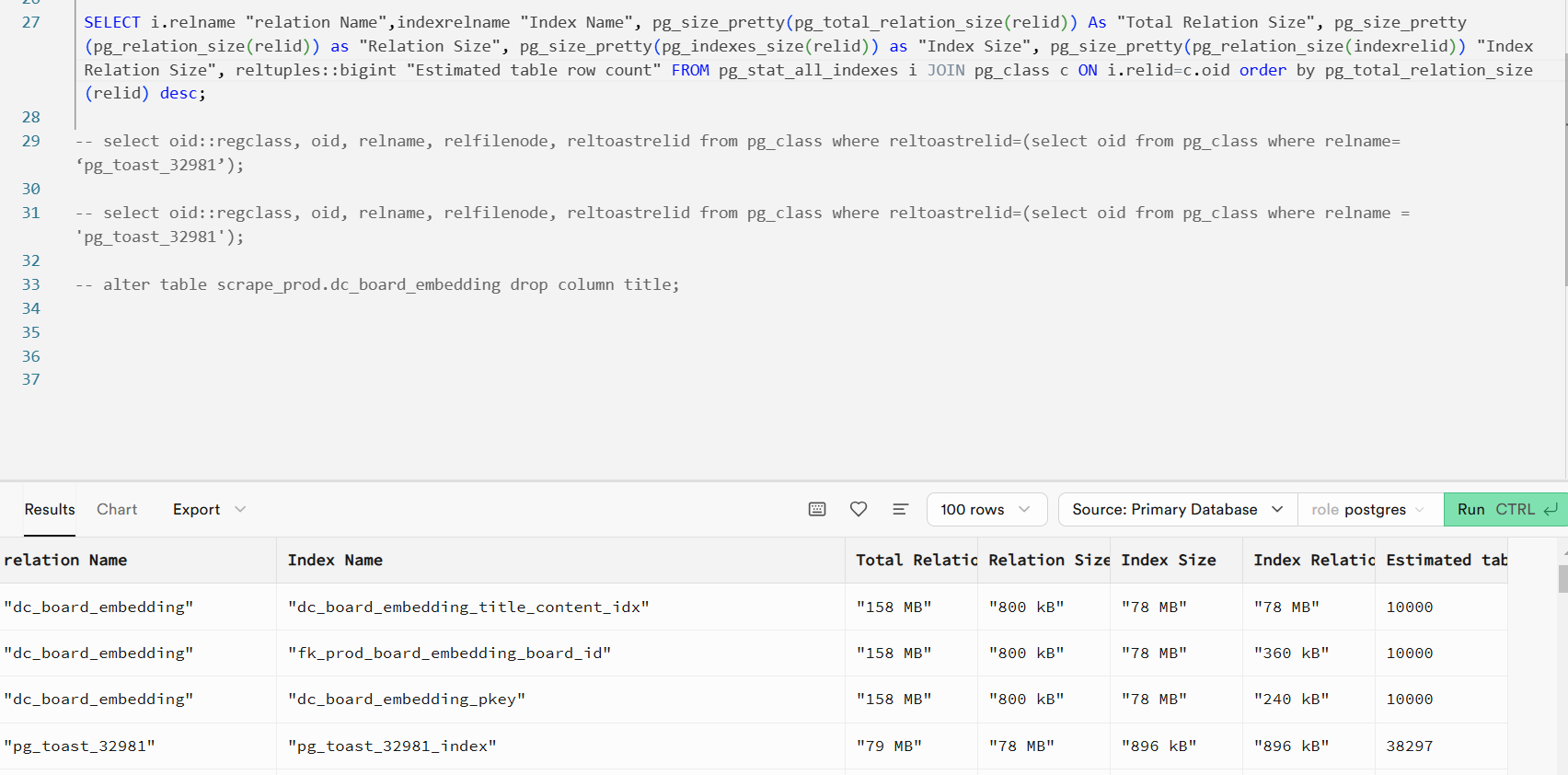
dc_board_embedding 테이블 10000 행의 총 용량이 158MB, 3만행 정도로 아마 다시 한계가 찾아올 듯 했다. (다만 위의 사진은 vacuum 이전이라 toast 용량이 높게 잡혀있다)
이 당시 supabase 의 report 메뉴에서 보여주는 DataBase Size 의 해당 테이블 용량은 78MB 였기 때문에, 왜 실제 사이즈 보다 적게 보여주는지 알아보니 report 메뉴의 DataBase Size 는 toast 용량을 제외한 relation size 와 index size 만 보여주고 있었다.
-- 전체 total relation size 포함 사이즈 출력
-- from https://stackoverflow.com/questions/41991380/whats-the-difference-between-pg-table-size-pg-relation-size-pg-total-relation
SELECT i.relname "relation Name",
indexrelname "Index Name",
pg_size_pretty(pg_total_relation_size(relid)) As "Total Relation Size",
pg_size_pretty(pg_relation_size(relid)) as "Relation Size",
pg_size_pretty(pg_indexes_size(relid)) as "Index Size",
pg_size_pretty(pg_relation_size(indexrelid)) "Index Relation Size",
reltuples::bigint "Estimated table row count"
FROM pg_stat_all_indexes i
JOIN pg_class c
ON i.relid=c.oid
ORDER BY pg_total_relation_size(relid) desc;
-- toast 연결 테이블 출력
select oid::regclass, oid, relname, relfilenode, reltoastrelid from pg_class where reltoastrelid=(select oid from pg_class where relname = '[toast 이름]');
SQL editor 에서 위의 sql 을 실행하면 toast 용량도 포함하여 확인할 수 있다.
글이 십만개가 넘는 만큼, 임베딩도 십만개가 넘어야 하기 때문에, 벡터값 자체의 크기를 줄일수 있는 방법을 찾기로 했다.
2.2 벡터 사이즈 축소 (1536 -> 256)
 |
 |
OpenAI 의 docs 와 블로그에서 볼 수 있듯 text-embedding-3 모델 부터는 벡터 사이즈를 변경하는 기능을 자체적으로 지원하며, 성능도 크게 차이나지 않는다고 한다. SpringAI 에서도 1.0.0 버전 부터 OpenAI API 요청시 벡터 사이즈 파라미터를 변경할 수 있는 기능이 추가되었으므로 text-embedding-3-small 에서 text-embedding-3-large 모델로 임베딩 모델 변경 후, 256 차원 벡터로 요청해 보았다.
String searchQuery = searchForm.getQuery();
EmbeddingResponse embeddingResponse = embeddingModel.call(
new EmbeddingRequest(
List.of(searchQuery),
OpenAiEmbeddingOptions.builder()
.withDimensions(256) // 256차원 크기의 벡터 요청
.build()));
float[] embeddedSearchQuery = embeddingResponse.getResult().getOutput();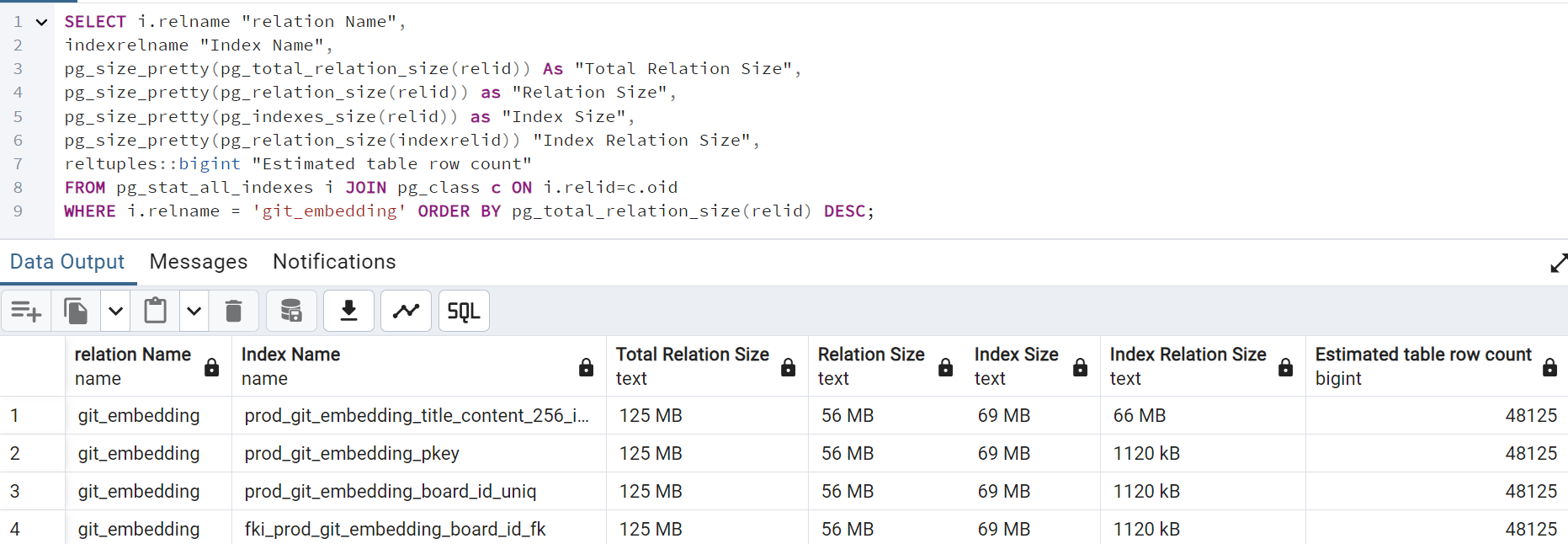
원래 1536차원 벡터의 경우 1만 행이 158MB 를 차지했던것에 비해 256차원 벡터의 경우 약 5만행이 125MB 정도를 차지하고 있는것을 확인할 수 있었다. 이정도면 내 기준으론 만족스러울 정도로 줄어들었기 떄문에 이 후 이대로 개발을 진행했다.
3. 이후
이후 어느정도 시간이 지나 임베딩 갯수가 16만개를 넘었을 무렵 DB 의 남은 용량은 다시 100MB 이하로 떨어졌고, 용량 외에도 DB 서비스가 다름에 따른 JOIN 및 연관관계 설정 불가능이라는 단점이 거슬려 결국 DB 호스팅서비스를 변경하기로 했다.
supabase 의 무료플랜의 다른 제한은 내게 큰 불만이 아니었지만, 결국 500MB 라는 용량의 한계를 극복하기 어려웠다. AWS 의 프리티어 RDS 의 경우 20GB 까지 설정이 가능하여 그쪽으로 DB를 전부 통합하였다.
supabase 는 AWS 에는 없는 편리한 웹 ui 가 있지만 느린 성능과 짧은 timeout, 적은 용량 등으로 인해 생각보다 그리 편리하지 않았다. AWS RDS 에 pgadmin 연결해서 쓰는게 개인적으로는 마음 편하고 좋았다.
'학습정리(공개)' 카테고리의 다른 글
| ElasticBeanstalk 배포 서비스에 Cloudflare https 적용 및 보안관련 수정 (0) | 2025.02.20 |
|---|---|
| Selenium Java 의 java.util.concurrent.TimeoutException 문제와 Playwright (0) | 2024.09.25 |
| JPA 쓰기 지연 저장소 flush 시점 관련 테스트 및 정리. (0) | 2024.06.06 |
| 아마존 리눅스 2023 Cloudwatch 로그 스트리밍 구성 설정 마이그레이션 후기 (0) | 2024.04.23 |
| 채팅앱 후기 - Thymeleaf 사용중 csrf 토큰 관련 에러 (0) | 2023.07.24 |



